
新型大模型能够对任意代谢酶进行活性预测和生成式设计改造
“从依赖公共数据,到自主建立高质量数据集的转变,是提升模型准确度的关键。”李斐然表示。
她长期致力于代谢网络模型研究,新型大模型能够对任意代谢酶进行活性预测和生成式设计改造涉及计算生物学、系统生物学、机器学习、化学、药物代谢等领域,曾获得瑞典查尔姆斯理工大学生物及生物工程博士学位,师从全球著名生物工程专家延斯·尼尔森(JensNielsen)教授。
目前,李斐然是与聚树生物合作共建“精确”酶工程大模型的科学家之一,担任清华大学深圳国际研究生院助理教授,特别研究员。
(来源:聚树生物)
“AI辅助‘精确’酶工程设计的核心在于高质量的数据集。基于典型工业酶的高通量活性测试,获得私有数据集,结合深度学习模型,以实现酶工程设计的标准化和精确化。聚树生物正朝着这个方向迈进。”清华大学教授、聚树生物科学创始人张翀表示。
首个酶活性预测“大模型”
酶不仅参与生物制造过程,其本身也是生物制造的重要产品。2023年,仅工业酶的全球市场规模价值就达到74亿美元。
对酶蛋白进行分子设计和改造,是创造高性能工业酶、降低生产成本、提升产业竞争力的关键。酶工程主要包括理性设计、定向进化、半理性设计和人工智能辅助设计等策略。
其中,AI技术在数据驱动下,可以学习有关蛋白质构成和进化的特征信息,其能够解决许多类型的酶工程问题。例如,预测具有有益影响的突变、优化蛋白质的稳定性、提高催化活性等。
然而,AI目前在蛋白质设计中面临诸多挑战。在酶的改造设计方面,AI难以精准预测微小扰动引起的结构变化[1-3]。
在酶的从头设计方面,AI面临的挑战更加复杂。
生成特定结构的世界领先水平模型成功率为15-50%,生成特定功能的世界领先水平模型成功率约为0.01%-60%(可溶性简单蛋白),生成高活性的世界领先水平模型成功率远小于10%[4-6]。
李斐然及其合作者首次开发了深度学习模型DLKcat和酶参数数据库GotEnzymes,能够实现大规模的酶活性表征。
kcat(酶周转数)是了解酶催化特性的重要动力学常数。DLKcat这一深度学习模型能够成功预测酶活参数kcat,只需输入底物SMILES信息和酶的蛋白质序列,就可以得到直观的具体酶动力学参数。
“在没有数据驱动或AI模型的前提下,这一点是很难实现的。”李斐然说。
图丨kcat预测的深度学习模型性能(来源:NatureCatalysis)
据了解,酶参数数据库GotEnzymes同样由李斐然创建,该数据库对目前已知的大多数酶进行了酶活参数预测,用户通过简单查询可以得到特定功能的高活性候选酶。
GotEnzymes的第一个版本覆盖绝大多数酶类,包含:超过580万类酶、2579万个酶-化合物对的预测周转数。
并且,每个对都标注了EC编号(EnzymeCommissionnumber,也称为酶学委员会命名法),涵盖8099个生物体,包括747种真核生物、6963种细菌和389种古菌。
图丨GotEnzymes中预测的周转数概述(来源:NucleicAcidsResearch)
可以直观地看到,真核生物通常每个生物体有更高的周转数。整个数据集的中位周转数为5s−1,且大多数值(75%)在1到100s−1之间,这与基于实验数据的研究一致。
按生物体分组,可以发现真核生物、细菌和古菌的中位周转数接近,而真核生物的中位数最低。按EC编号分组,可以发现异构酶(EC5.X.X.X)具有最高的中位数,而连接酶(EC6.X.X.X)最低,这与之前的发现一致。
GotEnzymes的性能将通过一个迭代机制,得到持续提升。通过在GitHub上的代码版本控制和可重复预测管道,可以在未来的时间点重新生成数据,以扩展对其他酶和其他参数的预测。
AI工具通过持续迭代,更多和更好的训练数据可以带来更好的预测。因此,预计GotEnzymes将随着训练数据的增加而提升性能。
此外,随着未来开发改进算法的部署,GotEnzymes用于预测不同参数类型的预测模块可以独立更新,快速发布数据库的更新版本。
最终,相关论文分别以《基于深度学习的kcat预测可改进酶约束模型重建》(Deeplearning-basedkcatpredictionenablesimprovedenzyme-constrainedmodelreconstruction)为题发表在NatureCatalysis[7]。
以及以《GotEnzymes:一个广泛的酶参数预测数据库》(GotEnzymes:anextensivedatabaseofenzymeparameterpredictions)为题发表在NucleicAcidsResearch[8]。
图丨相关论文(来源:NatureCatalysis、NucleicAcidsResearch)
其中,第一篇论文被NatureCatalysis期刊在新闻&视角专栏发文报道推荐。此外,由于机器学习在催化领域的广阔应用场景及其重要性,该论文入选了NatureCatalysis“MachineLearninginCatalysis”专栏的12篇焦点论文之一[9]。
美国宾夕法尼亚州立大学教授、代谢模型专家科斯塔斯·马拉纳(CostasMaranas)评价DLKcat“能够对任意代谢酶进行活性预测”[10]。
第二篇论文被美国国家科学院院士、合成生物学专家乔治·丘奇(GeorgeChurch)评价为“机器学习弥补机理模型参数匮乏,助力下一代细胞工厂设计”[11]。
华东理工大学教授、酶工程领域专家许建和表示,这一人工智能的研究成果是有里程碑意义的,其核心内容成功构建了一种基于深度学习的方法(DLKcat),可以从酶的序列和底物结构出发预测kcat,并可用于重构酶容量约束型基因组规模代谢模型,特别适用于表征酵母和真菌细胞的代谢过程。
1秒钟筛选100个酶
值得注意的是,上述kcat预测方法将大幅提升酶的工程改造效率。对于某类特定工业酶而言,未来若以更多标准化的实验数据加以迭代训练,相信DLKcat的预测精度和适用广度将日益完善。
据介绍,已发表的DLKcat为第一版本,酶活性预测模型的精度误差在1个数量级以内,这对于酶工程和酶设计领域来说,已经具有指导意义。
通过不断更新迭代,目前,基于DLKcat的GotEnzymes数据库已发展到第二版本。不仅能预测酶活性,还可实现酶亲和力、最适温度等各种指标的预测,精度也得到了大幅提升。
此外,其还可以进行一些模拟改造设计酶的结构(比如加脯氨酸、剪短、加入保守序列等方式)半生成式的酶改造,以优化酶的特性(比如温度稳定性等)。
“目前我们第二版本DLKcat以及GotEnzymes的水平处于行业领先水平。”李斐然说。
她表示,该数据库为那些不会编程的研究人员,大幅度降低了技术操作难度。他们可以直接在网站上找到目标酶,而不用再花时间和精力去从头学习如何构建深度学习模型。
在该技术突破后,引发了领域内对酶活性和酶参数预测研究的热潮。后续,有十余个课题组也陆续报道了酶参数预测的相关研究。
此外,有多个课题组运用GotEnzymes数据库,例如,天津大学元英进院士团队利用GotEnzymes预测酶活性[12]。
图丨深度学习模型的预测和解释的kcat的突变酶(来源:NatureCatalysis)
李斐然表示:“该模型对终端的算力要求低,甚至可以在笔记本电脑上直接使用。并且,1秒钟至少能够筛选出100个酶。”
该技术为合成生物学领域提供重要的工具,不仅能够减少选择的盲目性,还可以提供更加理性设计的酶选择性。
从应用层面来看,短期内,人们可以直接通过该模型针对任意酶、任意底物进行预测。并且,有望实现高活性、特定结构或耐高温、耐强酸环境等定制化的酶元件。
更进一步地,通过不断地将该技术的相关参数引入到系统生物学的数字生命的建模,有利于更好地模拟细胞表型进行细胞工厂设计、进化疾病的机制分析等。
值得注意的是,在酶设计或酶表征工具的应用推进方面,最关键在于不断迭代,以持续提升工具的性能。
实际上,目前基于公开数据训练的模型,在预测准确度上面临同样挑战,并没有本质区别。而未来,通过更多的私有数据,训练出更高精度的酶设计和酶表征工具,将具有更强的行业竞争力和更高的商业价值。
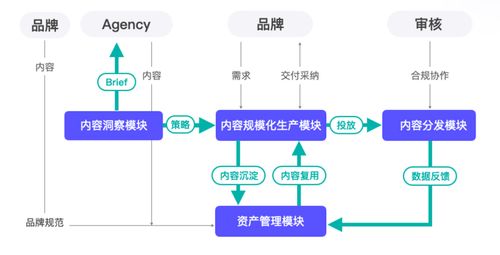
据了解,目前,聚树生物这家初创公司已与李斐然建立深度合作,共同开发“精确”酶工程大模型。
谈及这项研究,张翀表示,将基于高通量酶工程改造和活性检测技术平台,低成本、快速地构建高质量专用酶活性特征数据集,为深度学习模型提供精确和标注化数据,使深度学习模型在酶设计领域获得更高的精确度,实现酶设计领域的“数据-模型”飞轮效应。
如何生产高质量的专用酶数据?
张翀表示,针对AI大数据模型输出的新酶序列,需要对酶的实际性能进行系统表征,筛选“优质酶序列”、验证AI模型准确性,并通过测试/优化数据进一步完善校准AI模型,实现上述目标需要完成“新酶表达”及“新酶测试”两个主要环节。
传统的序列合成、底盘细胞转化、培养、蛋白纯化及酶活检测的方法始终面临人工效率低、实验成本昂贵的挑战,无法高通量验证AI数据模型产出新酶序列的性能及工艺参数。
聚树生物团队开发的autoHIPPS系统基于液滴微流控 自动化机械臂装备“高通量分子克隆-高通量单细胞培养-工程酶,制备纯化-酶活性快速检测”自动化实验流程,能够满足“新酶序列”的高通量、低成本的制备及酶特征活性评价及筛选全流程。
该过程每个环节均可以实现103~106个样本/天的测试量,高通量获取“优质酶序列”对应的“特征酶活性参数”,用于优化该类酶的AI大数据模型,快速提高优质序列预测的准确性。
李斐然表示,autoHIPPS系统通过高通量、低成本、全自动化的实验流程,为AI酶参数预测提供了大量高质量数据,将可以显著提升AI模型的预测准确性和效率。
据了解,autoHIPPS系统基于自动化工作站模块的“细胞培养-蛋白表达-纯化制备-自动化检测”流程,能够实现AI模型输出新酶序列实体蛋白的“快速制备-纯化-检测”,培养及酶纯化成本降低90%以上,酶性能测试预处理时间由1小时缩短至10秒。
基于标准酶活检测方法,对新酶序列的实体蛋白进行高通量性能测试评价(催化活性、底物特异性、热稳定性等)。获得最佳酶序列的同时,实现104~106个样本/天的测试数据集,为进一步优化AI大模型提供高准确性的优质数据。
张翀表示,通过autoHIPPS超高通量液滴微流控 机械臂自动化装备平台,实现新酶的“高通量实体蛋白制备、测试与评价”,所形成的高质量专有酶数据库,可以丰富AI新酶模型的评估及预测维度,加速模型迭代优化。
目标:覆盖从酶设计到提供酶产品的全链条
作为最全面和广泛使用的酶信息资源,BRENDA酶数据库几十年来一直在收集酶参数。截至2022年1月,BRENDA中的周转数为83662个,远少于GotEnzymes中计算预测的数量。
由于数据量庞大,李斐然表示,GotEnzymes将能够为包括实验和计算领域在内的生物学研究提供速度提升。
一方面,GotEnzymes准备提供基于预测参数的最佳酶,指导酶的选择和设计,从而减少合成生物学和代谢工程中的“设计-构建-测试-学习”周期的时间。
另一方面,GotEnzymes通过其应用程序编程接口(API,ApplicationProgrammingInterface),促进了跨生物体的计算分析。例如,进化分析和依赖大规模酶参数的代谢建模,如动力学模型和蛋白质组约束模型。
下一步,该团队将通过整合更多类型的酶参数来扩展GotEnzymes,利用可用的基于AI的预测,例如酶的温度最优化和米氏常数,从而满足用户的更多需求。
此外,他们还将实现来自其他数据库如MetaCyc和基于深度学习的注释工具的注释,以扩大初始版本中仅基于KEGG数据库生成的酶-化合物对的覆盖范围。
与此同时,研究人员还打算在MetabolicAtlas平台上的代谢路径图中叠加酶参数作为新层,预计这将实现交互式比较并促进高级模型开发。
在拥有高性能的酶序列后,或可用数据-机理混合驱动的底盘细胞设计技术实现其高效表达,从而实现从设计到生产的全链条过渡。
“未来,在用户提出具体的酶设计需求后,我们能够直接提供从设计改造到表达,再到酶产品的全链条服务。”李斐然表示。
参考资料:
1.JohnM.McBrideetal.AlphaFold2CanPredictSingle-MutationEffects.PhysicalReviewLetters131,218401(2023).https://doi.org/10.1103/PhysRevLett.131.218401
2.https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10019719/
3.https://www.nature.com/articles/s41594-021-00714-2
4.https://www.science.org/content/blog-post/protein-design-ai-way
5.https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9949690/
6.https://www.sciencedirect.com/science/article/pii/S0092867423014022
7.Li,F.,Yuan,L.,Lu,H.etal.Deeplearning-basedkcatpredictionenablesimprovedenzyme-constrainedmodelreconstruction.NatureCatalysis5,662–672(2022).https://doi.org/10.1038/s41929-022-00798-z
8.Li,F.etal.GotEnzymes:anextensivedatabaseofenzymeparameterpredictions.NucleicAcidsResearch51,D583–D586(2023).https://doi.org/10.1093/nar/gkac831
9.https://www.nature.com/collections/gfbfaeaibd
10.Boorla,V.S.,Upadhyay,V.&Maranas,C.D.MLhelpspredictenzymeturnoverrates.NatureCatalysis5,655–657(2022).https://doi.org/10.1038/s41929-022-00827-x
11.Yilmaz,S.,Nyerges,A.,vanderOost,J.etal.Towardsnext-generationcellfactoriesbyrationalgenome-scaleengineering.NatureCatalysis5,751–765(2022).https://doi.org/10.1038/s41929-022-00836-w
12.Zhang,R.etal.ModularCoculturetoReduceSubstrateCompetitionandOff-TargetIntermediatesinAndrostenedioneBiosynthesis.ACSSyntheticBiology12,3,788–799(2023).https://doi.org/10.1021/acssynbio.2c0059
运营/排版:何晨龙
支持:何思源









